By default, LoadRunner uses its own sockets implementation, which is very robust and allows use of hundreds of virtual users per load generator during a test. However, under certain conditions the sockets implementation does not seem to work. Or so it seems.
During one of our client engagements, recording of a script using Web (HTTP/HTML) protocol proceeded smoothly. However, its replay failed. The target URL failing was using https protocol. The error recorded in Vugen was step-download timeout exceeded which was set to the default of 120 secs. This is a common error that typically means something went wrong and the server did not return a response to the client’s request within the timeout value. The URL in question simply fetched a WSDL. All major browsers (IE, Firefox and Chrome) on that machine were able to successfully retrieve the WSDL without any issues. Turning on Advanced trace and Print SSL options in VuGen did not provide any clues. It seemed like LR was making the request but nothing much was being returned from the server.
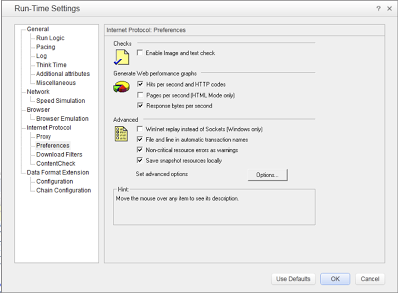 Turning on the WinInet option in run-time settings of VuGen immediately made the output window of VuGen a beehive of activity. The server responded immediately. This option essentially allows LoadRunner to use Internet Explorer’s HTTP implementation under the covers. Using this option, everything that IE can do is made available to LoadRunner. Unfortunately, the use of WinInet option comes with a penalty. According to LoadRunner documentation (v.11.51), this option is not as scalable as the default sockets implementation. HP product support indicated that if using WinInet option allows script replay then that is our only option. Luckily, we found a workaround by staying patient and using Wireshark to look under the covers. Incidentally, Wireshark is a fantastic tool to add to your performance testing arsenal if you haven’t already.
Turning on the WinInet option in run-time settings of VuGen immediately made the output window of VuGen a beehive of activity. The server responded immediately. This option essentially allows LoadRunner to use Internet Explorer’s HTTP implementation under the covers. Using this option, everything that IE can do is made available to LoadRunner. Unfortunately, the use of WinInet option comes with a penalty. According to LoadRunner documentation (v.11.51), this option is not as scalable as the default sockets implementation. HP product support indicated that if using WinInet option allows script replay then that is our only option. Luckily, we found a workaround by staying patient and using Wireshark to look under the covers. Incidentally, Wireshark is a fantastic tool to add to your performance testing arsenal if you haven’t already.
Making a recording of the traffic in Wireshark while the URL was accessed in Internet Explorer and comparing it to a recording made while the LoadRunner script was replayed in VuGen showed a problem during SSL handshake. The difference was immediately apparent just watching the traffic in Wireshark (best to use a display filter if your network is as chatty as our customer’s). IE was using TLSv1 protocol in order to make the request to the server while LoadRunner was trying SSLv1 and SSLv2 protocols, which although dated are still popular. It is not clear if the server itself was configured to respond only to TLSv1. But LoadRunner NEVER tried to use TLSv1 during handshake with the server. A quick read of VuGen’s documentation clarified that LoadRunner uses only SSLv1 and SSLv2 by default. By using web_set_sockets_option(“SSL_VERSION”,”TLS”) function and AND turning off the WinInet option allowed replay to work without a hitch. As a result we now have a scalable scenario to test our web application.
Incidentally, you can also verify which version of SSL is being used for client-server communication by using the
openssl binaries that ship with LoadRunner. For example, to verify which version of SSL is used to connect to google.com, try the following:
- Navigate to the folder containing openssl.exe (typically <LoadRunner installation folder>/bin on Windows).
- Enter openssl s_client -connect google.com:443
For your environment, replace google.com with your server name and 443 with the port number on which https traffic is handled.
You will see something like the following output (only the relevant lines are shown)
—
SSL handshake has read 1752 bytes and written 316 bytes
—
New, TLSv1/SSLv3, Cipher is RC4-SHA
Server public key is 1024 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : RC4-SHA
Session-ID: F02931AD5F99B4FE65B52A8ACAEFB8378E6C4B0F89A0A71BC28A030236B3F8AA
Session-ID-ctx:
Master-Key: E1A9015993DD7D7EBDE13313AAA0DB768EA6644944FAE7F4AFE6B730061D4E0FB9F5A511616ACCBF073BCBDF90505FF2
Key-Arg : None
Start Time: 1360550907
Timeout : 300 (sec)
Verify return code: 0 (ok)
—
The highlighted text shows the protocol in use between the client and the server.